This post was originally written on 09/11/2012 but for various reasons it couldn’t be published earlier. It won’t be very technical, it’s mostly a behind the scenes view of how some of us at NOC GRNET tried to cope with an extreme spike of demands of a specific service we support.
Intro
At GRNET we provide a live streaming service to the Hellenic Parliament, who also connect to the Internet through our network. What we’re doing is that we’re serving the official TV channel of the Hellenic Parliament (the WebTV program actually). We have a machine that encodes (transcodes actually) video/audio and a separate streamer that serves the content to the clients via RTSP, RTMP and HTTP. While this service has been running for quite some time, and the streaming server has been used in various other occasions, it typically serves no more than 100 concurrent clients. With a stream at 640Kbps on average that’s abound 60Mbps of streaming traffic. The number of viewers usually goes up only when there’s something exciting going on. Our previous traffic spike was at 577Mbps on October 31st, when the Minister of Finance was presenting the budget for 2013 to the Parliament. What happened that day was that news reporters were on strike and it seems that one of the few news sources available at the time for people to use was the Parliament channel, either on the TV or through our stream. The viewership that day surpassed all previous expectations but the streaming system actually performed quite well considering we didn’t have any complaints.
Remember, remember the 7th of November
On the 7th of November almost everyone was on strike in Greece. There was a huge march arranged at 17:00 outside of the Greek Parliament to protest against the new harsh measures of Memorandum III that the parliament was to vote for at midnight.
We started seeing some traffic arriving, well leaving is more accurate, our streaming server at around 10:00 in the morning. Some news sites and blogs (tanea.gr, left.gr, protothema.gr) had already started posting links to our parliament’s streaming service for people to watch the discussion that was already taking place. At around 10:30 we were already serving more than 100Mbps while the traffic was steadily rising. A bit after 12:00 though things got really nasty. Websites like tovima.gr, zougla.gr and newsit.gr had posted our streaming links in their very first page. The discussions both inside the parliament and on the social networks had also started heating up. At 12:25 the traffic starting ramping up extremely fast!
12:25 160Mbps
12:32 367Mbps
12:38 597Mbps
12:42 756Mbps
12:49 779Mbps
That’s when traffic stopped growing any more. We actually saw some drop in the traffic and then up to 780Mbps and down again. It was obvious that we had reached some limit. It wasn’t very obvious though what the bottleneck was since the streaming system load was quite low, around 0.6-1.0 in a 4 vCPU VM and it also had a virtio-net/gigabit[1] network card. Theoretically it should be able to push at least 100-150 more Mbps. In order to cope with the increasing demand we changed the player web page in order to off-load some users to an experimental service that relies on IP multicast from the server and P2P between the clients for delivering streams. This bought us some time, about 2-3 hours. Also maybe because it was noon time, or due to more people using the experimental service or not being satisfied from the performance of the streaming video and disconnecting, traffic later on dropped “down” to an average of 650-700Mbits.
We started discussing short-term actions for improving the service so as to be able to cope with more demand. The streaming server was running on GRNET’s virtualization platform, which is based on ganeti, and the first thought we had was to try and add more network cards to the VM and somehow bond the cards together. Could we push more than 1Gbps from the same VM? The problem was that we couldn’t do any 802.3ad bonding since the “virtual switch” inside the virtualization platform did not support such features. One other solution would be to add another virtual network card and use Linux bonding mode 5 (balance-tlb) or 6 (balance-alb). After a bit of reading this mode was rejected as well. These two bonding modes expect from the ethernet card running on the machine to support ethtool to read their speed. Our VMs use virtio-net which doesn’t support this functionality for ethtool. We could switch to another type of network card, e1000 for example, but this could have an unmeasured/untested performance penalty which could actually negate the addition of a second network card.
Hundreds of thousands of Greeks were planning to join this huge protest starting at 17:00 and so were some of us working at GRNET, at least I was. We had to make a decision though, drop our plans and improve the streaming service to help more people, especially Greeks living abroad, to access the stream or just join others at Syntagma square? Our shift was ending soon anyway. We decided to stay at work and try and improve the service as far as we could.
The path we chose in order to “scale” was to create to a second instance of the streamer and try to “balance” client requests to both streamers using round robin DNS. That involved creating a checkpoint of the running VM at our storage system, copy the running VM’s image from that checkpoint as a new image and run a new VM with that image. So we would be cloning the current streaming service while the service was running and serving clients (take that Windows!).
So we provisioned a new Debian server through LDAP, added the copied image disks at the VM’s configuration, booted the VM, run puppet to change the configuration files according to the new hostname and IP, and we were ready to serve more clients. After some testing we created a RR DNS entry, “streamer-frontend.domain.gr” which pointed to both first-streamer.domain.gr and second-streamer.domain.gr and had a TTL of 60. Changing the landing page though to serve streamer-frontend.domain.gr as the streamer url wasn’t enough. The first problem was that there were news sites and blogs that had copied directly our first streamer’s URL instead of the live.grnet.gr/paliament/ landing page, which actually runs on a different system and is served by an Apache2 server (more on that later). Having already more than 1000 streams on the first streamer and then starting to do RR DNS on both servers meant that there would still be a large number of clients served by the first server and new people getting directed there would only make matters worse, while people directed to the second server would have a much better service experience. So what we actually did was point streamer-frontend.domain.gr not on both first-streamer.domain.gr and second-streamer.domain.gr but just second-streamer.domain.gr. We also changed the IP address of first-streamer A,AAAA records to second-streamer’s IP and flushed the first-streamer RR at our caching resolvers. Since many people use our caching resolvers, especially students with DSL lines, we were able to direct even more people towards the second-streamer.
Before adding second-streamer.domain.gr:
* first-streamer.domain.gr -> 1.2.3.4 TTL 86400
* live.grnet.gr/parliament/ pointing the streamer URL at first-streamer.domain.gr
After adding second-streamer.domain.gr:
* streamer-frontend.domain.gr -> 1.2.3.5 TTL 60
* first-streamer.domain.gr -> 1.2.3.5 TTL 60
* second-streamer.domain.gr -> 1.2.3.5 TTL 60
* live.grnet.gr/parliament/ pointing the streamer URL at streamer-frontend.domain.gr
That way people disconnecting from the stream and reconnecting some time later on were pointed to the new server, if they used our landing page. That meant better quality streaming for both “old” clients getting their stream from first-streamer, and for the new clients that were being served from second-streamer.
Within 30 minutes since booting up, the second streamer was serving more than 250Mbps and after another 30′ its traffic had climbed up to 450Mbps while first-streamer was steadily serving more than 550Mbits. That lead us to an all time record of 1.02Gbps at 17:45. At that point we were serving more than 2000 concurrent streams. A number we never expected for this humble streaming service.
While traffic was increasing through the addition of the second streamer, another problem came up. Some misconfigured clients and HTTP proxies were opening up connections at the Apache 2 serving the web page and never closed them down. We hit Apache’s internal ServerLimit variable of 256 around 17:00. We had to increase ServerLimit inside Apache’s config and restart it:
ServerLimit 500
<IfModule mpm_prefork_module>
StartServers 10
MinSpareServers 15
MaxSpareServers 25
MaxClients 500
MaxRequestsPerChild 0
</IfModule>
After some minutes of happiness another “unexpected” issue came up. It started to rain in Athens, so people who were at the protest at Syntagma square would probably leave soon and go home. There would certainly be an increase in traffic. And what about midnight, which is when the MPs were supposed to vote on the new measures? People would be sitting at their computers, bashing the politicians on Twitter and Facebook while watching the Parliament’s stream. At the same time we started seeing a big increase in international traffic, since more Greeks living abroad were tuning in; this stream was probably the only way they could watch what was happening at the Parliament.
That only meant one thing. Hello third-streamer! 10′ later we had another streamer running. But we also wanted to make some changes to the first two VMs. We wanted to add more vCPUs, going from 4 to 8, add more RAM, going from 4096Mb to 6144Mb, and do some minor performance tuning on the software. That meant restarting the VMs in order to activate the additional resources… luckily the chairman of the Parliament announced a 10 minute recess some time around 19:30. That was our chance… we changed back first-streamer’s IP address, added it to streamer-frontend RR DNS while also adding third-streamer to it. Then we rebooted the first two VMs. After 30″ we had 3 streamers running and waiting for clients to join them. third-streamer instantly got more than 200Mbps at the very moment we rebooted the other 2 VMs.
After adding third-streamer.domain.gr:
* streamer-frontend.domain.gr -> {1.2.3.4 | 1.2.3.5 | 1.2.3.6} TTL 60
* first-streamer.domain.gr -> 1.2.3.4 TTL 60
* second-streamer.domain.gr -> 1.2.3.5 TTL 60
* third-streamer.domain.gr -> 1.2.3.6 TTL 60
* live.grnet.gr/parliament/ pointing the streamer URL at streamer-frontend.domain.gr
At 20:10, some of us decided to leave work after 11 hours, having 3 streamers running that had already reached 1.2Gbps of traffic. There were more than 2800 concurrent users at the time…
Our assumptions for midnight came true. Around that time, more than 4000 people had tuned in to the parliament’s stream and we were pushing about 1.66 Gbps. That was probably the all-time record for a single service in GRNET.
A big problem we didn’t solve that night
Unfortunately, each client gets a unique session id from the streamer, also when requesting an HTTP stream. These are not shared among the streamers, so if you send a subsequent HTTP request to a different streamer, who does not track that session id, it will not serve the request as expected but rather prompt the client to start a new session. Since some browsers did not cache the RRs of streamer-frontend long enough (remember that low TTL?) they would spread their requests to all the streamers. We knew this was happening but there was no way to solve this without extensive changes to the setup, which would have to be tested of course would mean significant downtime for the service. Therefore, depending on the browser people used, some got better or worse service than others. The good thing is that we know how to fix this in the future.
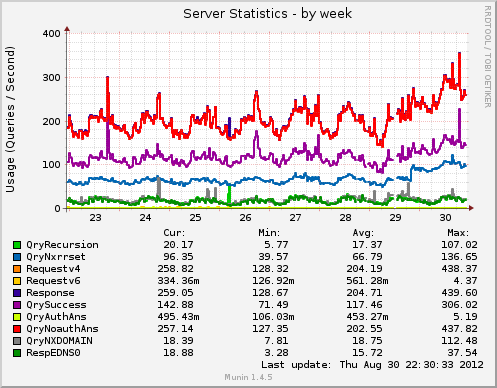
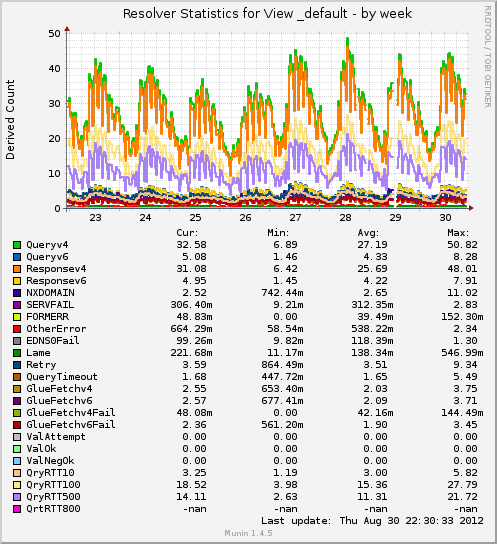
Some Stats & Graphs
more than 31000 unique IPs connecting to the streaming service
more than 4000 concurrent users at peak time
more than 4.7 TB of data streamed
first-streamer ethernet traffic:

second-streamer ethernet traffic:

third-streamer ethernet traffic:

Streamer client types

Streamer LAN traffic aggregates:

Create your own graphs here: http://mon.grnet.gr/rg/157184/details/
Epilogue
Yeah, there were hiccups in the stream for many many people, we acknowledge that. But we certainly did the best we could to keep the service running. Could we have done better ? Yes we could, but we would have to re-design the service and make some drastic changes that were never tested before. We didn’t want to risk making drastic changes that might not work at all while we could somewhat “scale” our service using a “working” solution. I wonder what will happen on Sunday when the Parliament votes for 2013 budget…Will we exceed our previous peak? We’ve already discussed alternatives to cope with the extra traffic and we’ll definitely be better prepared [2]!
I think that zmousm, alexandros and me did a fairly good job regarding the circumstances. We should buy each other a beer sometime..We’ll treat faidonl another one though for his helpful consulting 🙂
Since no external CDNs or other services provided by companies abroad were used, this might be the event with the biggest ever demand in network resources served from within Greece.
Do you like solving such problems ? Then there might be a lurking sysadmin inside you 😉
[1] After a talk with apoikos, he corrected me saying that virtio-net does not have a “gigabit” capacity. Virtio-net’s capacity is only limited by the node resources available, so it can theoretically perform better than gigabit. So our thoughts on using balance-alb/tlb to cope with the extra bandwidth were wrong. This clue points out that the cause of bottleneck on the streamer that couldn’t go over 800Mbps was the streamer software itself since both VM’s and hardware node’s system load were low.
[2] On 11/11/2012 the Greek Parliament voted for 2013 budget. What we did prior to that day to cope with the traffic was to setup a new version of the streamer software, that actually came out on 08/11/2012 just one day after the initial spike, that had the option to disable session IDs. Then it was quite straightforward to add some varnish caches in front of the streamers to serve the HTTP streams to the clients. Unfortunately client demand was somewhat lower, it only reached 0.92Gbps.
 Filed by kargig at 10:46 under Encryption,Internet,Privacy
Filed by kargig at 10:46 under Encryption,Internet,Privacy 2 Comments | 16,344 views
2 Comments | 16,344 views